
導讀:在現代自動駕駛任務中,決策規劃模塊依賴于多個感知、預測任務模塊以提供充足的環境信息,其中感知任務不僅需要檢測場景中的動態物體,還需要識別道路邊界、人行橫道、車道線、路標等靜態元素。而預測任務需要系統能夠推理其它動態物體的運動趨勢,為決策提供信息依據,規劃出道路從而避免碰撞。
目前業界基于純視覺的感知、預測算法研究通常僅針對上述流程中的單個子問題的image-view方案,如3D目標檢測、語義地圖識別或物體運動預測,通過前融合或后融合的方式將不同網絡的感知結果進行融合。這導致了在搭建整體系統時只能以線性結構堆疊多個子模塊。
盡管上述方式能夠實現問題分解、便于獨立的學術研究,但這種串行架構具有幾個重要的缺陷:
(1)上游模塊的模型誤差會不斷向下游傳遞,然而在子問題的獨立研究中通常以真值作為輸入,這使得累積誤差會顯著影響下游任務的性能表現
(2)不同子模塊中存在重復的特征提取、維度轉換等運算過程,但是串行架構無法實現這些冗余計算的共享,不利于提升系統的整體效率
(3)無法充分利用時序信息,一方面,時序信息可以作為空間信息的補充,更好地檢測當前時刻被遮擋的物體,為定位物體的位置提供更多參考信息。另一方面,時序信息能夠幫助判斷物體的運動狀態,在缺少時序信息的條件下,基于純視覺的方法幾乎無法有效判斷物體的運動速度。
區別于image-view方案,BEV方案通過多攝像頭或雷達將視覺信息轉換至鳥瞰視角進行相關感知任務,這樣的方案能夠為自動駕駛感知提供更大的視野并且能夠并行地完成多項感知任務,那么BEV感知能夠成為下一代自動駕駛感知算法風向嗎?
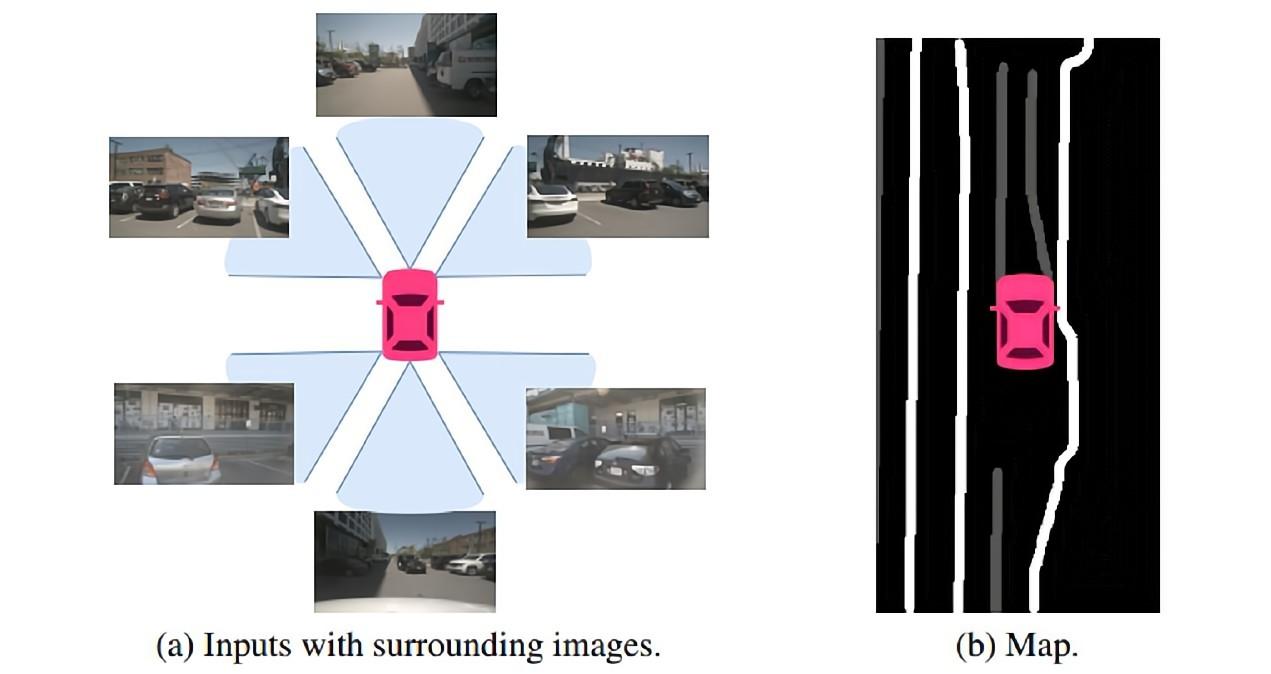
BEV空間下地圖分割任務,截圖自"UniFormer"(Qin et al., 2022)
一、BEV的發展歷史
在BEV空間中,傳統的BEV變換算法通常是在圖像空間中進行特征提取,并產生分割結果,再利用逆透視變換(IPM)將其轉化為BEV空間。

兩個輸入圖像(a)和(b)以及它們對應的IPM投影圖像,分別是(c)和(d),截圖自"Multimodal inverse perspective mapping"(Oliveira et al., 2015)
IPM的功能是消除視覺上的影響,比如,在自動/輔助駕駛中,因為在前視的照相機拍攝的圖像中,原本平行的物體會因為透視的原因而發生交叉。
IPM是把影像與BEV空間連接起來的一種簡便、直接的方式,要得到一幅影像的IPM,就必須了解攝像機的內參(焦距、光心)和外參(俯仰角、偏航角和地面高度)。在這個過程中,攝像機必須保持俯仰角,但這種約束太嚴格,難以在實際應用中得到滿足。同時,由于參數的變化,會引起系統對物體的感知能力的變化,從而降低視覺質量,造成平行車道之間的夾角。
為減小俯仰角對視覺的影響,在改進后的算法中,采用了攝像機的實時位姿,并將俯仰校正添加到相鄰的幀中,這樣可以獲得較好的逆變換效果,但由于實時位姿難以精確地獲得,因而無法獲得最理想的結果。
這兩年BEV相關算法的發展讓深度學習應用于BEV空間轉換的方式逐漸成為主流。與以往的算法相比,利用神經網絡進行二維BEV空間變換可以獲得更好的視覺效果。
該方法主要流程是:首先利用主干網對各個攝像機進行特征提取,再利用Transformer等技術將多攝像機數據從圖象空間轉化為BEV空間。在BEV空間中,由于利用同一坐標系統,可以很方便地將Lidar、Radar等傳感器數據與其他傳感器數據進行融合,還可以進行時序融合形成4D空間,這也是當下BEV技術的大趨勢。
三、BEV的優勢
1、跨攝像頭融合和多模態融合更易實現
傳統跨攝像頭融合或者多模態融合時,由于數據空間的差異,需要用很多后處理規則去關聯不同傳感器的感知結果,操作非常復雜。而在BEV空間內進行多攝像頭或多模態融合后,再做目標檢測、實例分割等任務,可以使算法的實現更加簡單,也能更直觀地顯示出BEV空間中的物體大小和方向。
2、時序融合更易實現
在BEV空間中,可以很容易地實現時序信息的融合,從而構建一個4D空間。在4D空間內,感知算法能夠更好地完成諸如速度測量等感知任務,并能將運動預測的結果傳遞到下游的決策和控制模塊。
3、可“腦補”出被遮擋的目標
由于視覺的透視效應,現實世界的物體在2D圖像中很容易受到其他物體的遮擋,因此,傳統的基于2D的感知方式只能感知可見的目標,對于被遮擋的部分算法將無能為力。而在BEV空間內,算法可以基于先驗知識,對被遮擋的區域進行預測,“腦補”出被遮擋的區域是否有物體。雖然“腦補”出來的物體固然有“想象”的成分,但對后續的控制模塊來說,還是有不少益處。
4、端到端的優化更加容易
在傳統感知任務中,識別、跟蹤和預測更像是個“串行系統”,系統上游的誤差會傳遞到下游從而造成誤差累積,但在BEV空間內,感知和預測都是在一個統一的空間中進行的,因此,可以通過神經網絡直接做端到端優化,“并行”出結果,這樣既可以避免誤差累積,又可以極大地降低算法邏輯的影響,讓感知網絡能夠以數據驅動的方式來自學習,進行更好的功能迭代。
三、BEV感知,是下一代自動駕駛感知風向嗎?
回到本文開頭的問題,BEV感知能夠成為下一代自動駕駛感知算法風向嗎?通俗的講,BEV感知相當于給自動駕駛開啟了“上帝視角”,能夠讓車輛無遮擋的“看清”道路上的實況信息,在BEV視角下統一完成感知和預測任務。
在傳統的image-view方案中,3D目標檢測、障礙物實例分割、車道線分割、軌跡預測等各項感知任務互相分離,使得該方案下的自動駕駛算法需要串聯多個子模塊,極大增加了算法的開發、維護成本。而BEV感知能夠讓這些感知任務在一個算法框架上實現,大大減少人力需求。
綜合前文所述的BEV優勢,當下不少的研究機構和各大車企都在推動BEV方案的落地,基于來自傳感器輸入層、基本任務和產品場景的不同組合,可以給出相應的BEV算法,例如,M2BEV和BEVFormer屬于純攝像機路線的算法,從多個攝像機獲取圖像信息來執行多種任務,包括3D目標檢測和BEV地圖分割等。BEVFusion設計了一個BEV空間的多模態融合策略,同時使用攝像機和LiDAR作為輸入完成3D檢測和跟蹤任務。特斯拉發布了其系統化的pipeline,在矢量空間(BEV)中檢測物體和車道線,用于二級公路導航和智能召喚。
可以肯定的是,BEV感知算法能夠更好地融合多傳感器的特征,提高感知和預測的準確率,在一定程度上可以提升自動駕駛技術。
BEV感知是否能夠成為自動駕駛的“答案”還有待時間驗證。而在剛過去不久的特斯拉AI Day2022中,特斯拉提出的Occupancy Network在BEV的基礎上加上了Z軸的信息,引入的occupancy grid可以用于表示任意形狀的物體和任意形式的物體運動。Occupancy Network是否又能將自動駕駛帶到一個新的高度?我們將在后續系列的推文中介紹并一起探討關于特斯拉的自動駕駛解決方案。






