
導讀:ChatGPT可以做什么?可以取代Jack寫文章,通過Jack過去文章的學習,AI可以總結出Jack寫文章的結構和套路。之后可以輸入文章的核心以及相關數據,他可以快速形成Jack的文章;可以取代Jack上班做PPT,特別是匯報總結類的PPT,它都可以快速形成。
這是真的,顯然ChatGPT這類通用AI大模型未來可以顛覆很多東西。那么對于ChatGPT這類技術還真應該了解。

所以本文結合相關信息,進行總結:
(1)什么是ChatGPT,他能夠干什么?
(2)ChatGPT背后的技術是什么?
(3)ChatGPT當前有什么局限性?
(4)ChatGPT國內外有哪些同類產品?
(5)ChatGPT對于汽車技術有什么影響?
幫助自我認知學習,也希望能夠給大家帶來一些信息和啟發。
一、什么是ChatGPT,他能夠干什么?
ChatGPT,首先回歸它英語的意思Chat就是聊天,GPT是Generative Pre-trained Transformer的縮寫,翻譯成生成式預先訓練的Transformer,Transformer是完全基于自注意力機制的一個深度學習模型。所以ChatGPT是可以聊天的生成式的、預先訓練好的算法模型。它屬于當前火熱的生成式AI人工智能模型,也就是AI生成人類內容。
ChatGPT對于普通的使用者是一種人工智能聊天機器人,當前主要基于文字聊天,它使用高級自然語言處理(NLP) 與人類進行逼真的對話。目前ChatGPT 可以生成文章、虛構故事、詩歌甚至計算機代碼。ChatGPT 還可以回答問題、參與對話,在某些情況下,還可以對非常具體的問題和查詢提供詳細的答復。
其實聊天機器人可不算什么新鮮玩意,它通過關鍵詞搜索技術,然后匹配回答,這個在我們日常生活中很常見,比如說亞馬遜的Alexa,蘋果的SIRI,天貓精靈,百度小度等等還有不少在線客服,甚至我們熟悉的汽車語言控制,他們主要是基于任務的命令式語音助手。但是ChatGPT確是采用更加精致的大數據訓練模型,應用范圍更廣,可以集成到各種應用中。
ChatGPT 有別于其他聊天機器人和 NLP 系統的一件事是其超現實的對話技巧,包括提出后續問題、承認錯誤和指出主題細微差別的能力。在許多情況下,基本上如果不是告訴你,人類是很難檢測到自己是正在與計算機生成的機器人進行交互。語法和語法錯誤很少見,書面結構合乎邏輯且清晰。
ChatGPT 的一些功能包括:
生成模仿輸入數據的樣式和結構的類人文;
生成對給定提示或輸入文本的響應。這可能包括寫故事或回答問題;
生成多種語言的文本;
修改生成文本的樣式(例如,正式或非正式);
提出澄清問題以更好地理解輸入數據的意圖;
回復與對話上下文一致的文本,例如提供后續說明或理解對先前問題的引用;
其他生成式 AI 模型可以對圖像、聲音和視頻執行類似的任務。
另外,ChatGPT可以進行微調訓練:通過在較小的相關數據集上進行訓練,使 LLM 適應特定任務或領域的過程,這也是ChatGPT目前拓展的商業模式,某個細分領域的應用例如專業的法律顧問,專業的汽車智庫專家。
二、ChatGPT背后的技術是什么?
ChatGPT 是 OpenAI 的最新語言模型NLP(Natural language processing),它是基于大型語言模型LLM(Large Language Model )模型GPT-3 加上使用監督學習和人類反饋強化學習 RLHF(Reinforcement Learning from Human Feedback) 的特殊技術來微調 ChatGPT形成。
其中三個技術關鍵詞:
NLP(Natural language processing)自然語音處理;
LLM(Large Language Model )大型語言模型;
RLHF(Reinforcement Learning from Human Feedback) 人類反饋中的強化學習;
NLP自然語言處理,就是人類語言與計算機之間的交互,范圍比較大。NLP領域流行的技術是深度學習模型,主要依托于以下幾項關鍵技術:魔改的LSTM模型及少量的改進CNN模型,RNN作為典型的特征抽取器;以Sequence to Sequence(或叫encoder-decoder亦可)+Attention作為各種具體任務典型的總體技術框架。
LLM大型語言模型,就是目前ChatGPT所屬的模型,是人工智能的一個子集,顧名思義“大“,就是海量數據,它已經在大量文本數據(例如ChatGPT的拓展基礎ChatGPT3.0 的數據背后是整個互聯網和幾百萬本書大概3千億文字)上進行了訓練,可以對對話或其他自然語言輸入產生類似人類的反應。
它的主要關鍵技術點是:
詞嵌入:LLM 中使用的一種算法,以數字形式表示詞的含義,以便將其輸入 AI 模型并由其處理,通過將單詞映射到高維空間中的向量來實現的,其中具有相似含義的單詞靠得更近。
注意機制:LLM 中使用的一種算法,它使 AI 在生成輸出時能夠專注于輸入文本的特定部分,例如文本中與情感相關的詞。這樣使LLM 考慮給定輸入的上下文或情緒,從而產生更連貫和準確的響應。
Transformers:LLM 研究中流行的一種神經網絡架構,它使用自注意力機制來處理輸入數據,從而使它們能夠有效地捕獲人類語言中的長期依賴關系。
Transformer 經過訓練可以分析輸入數據的上下文,并相應地對數據的每一部分的重要性進行加權。由于這種類型的模型學習上下文,它通常用于自然語言處理 (NLP)以生成類似于人類書寫的文本。由于它的注意力機制它比之前的RNN,GRU 和 LSTM等深度學習算法具有極長的記憶力,Transformer可以“參與”或“關注”之前生成的所有令牌。理論上,注意力機制在提供足夠的計算資源的情況下,有一個無限的窗口可供參考,因此能夠在生成文本時使用故事的整個上下文。
大型語言模型(例如 GPT-3)根據來自互聯網的大量文本數據進行訓練,能夠生成類似人類的文本,事實上,他們的目標函數是單詞序列(或標記序列)的概率分布,使他們能夠預測序列中的下一個單詞是什么(下面有更多詳細信息),所以它們可能并不總是產生與人類期望或理想值一致的輸出。
然而,在實際應用中,LLM模型訓練的目的是執行某種形式的有價值的認知工作,并且這些模型的訓練方式與我們希望使用它們的方式之間存在明顯差異。盡管從數學上講,機器計算出的單詞序列的統計分布可能是對語言建模的一種非常有效的選擇,但作為人類,我們通過選擇最適合給定情況的文本序列來生成語言,并使用我們的背景知識和常識來指導這個流程。
當語言模型用于需要高度信任或可靠性的應用程序(例如對話系統或智能個人助理)時,LLM的表現的問題就有:
缺少幫助:不遵循用戶的明確指示;
幻覺:模型編造了不存在的或錯誤的事實;
缺乏可解釋性:人類無法理解它是如何做出特定決定或預測的。
生成有偏見或有害的輸出:在有偏見/有害的數據上訓練的語言模型可能會在其輸出中重現該結果。
但 ChatGPT 的創建者究竟是如何利用人類反饋來解決對齊問題的呢?這時就需要對LLM進行RLHF(Reinforcement Learning from Human Feedback) 人類反饋中的強化學習。該方法總體上由三個不同的步驟組成:
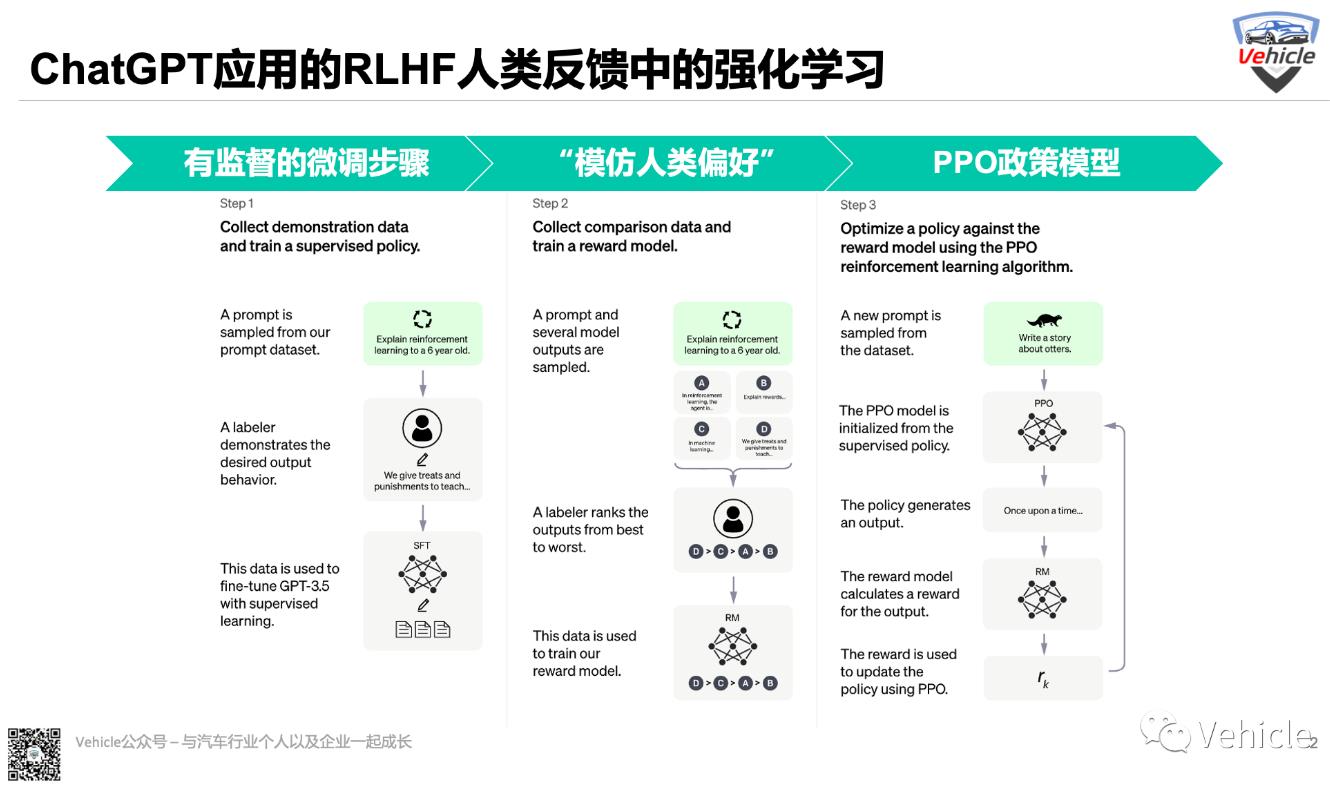
有監督的微調步驟:首先類似于自動駕駛標記,先人工標記者寫下預期的輸出響應去訓練LLM例如ChatGPT就是微調GPT-3.5 系列。但是顯然人工標記成本很高,也聽說Open AI資本投資不少在這個方面,所以監督學習步驟的可擴展性成本很高。
“模仿人類偏好”步驟:這個階段人工標記者被要求對相對大量的 SFT 模型輸出進行投票,這樣就創建了一個由比較數據組成的新數據集。在此數據集上訓練了一個新模型。這稱為獎勵模型 (RM)。對于貼標機來說,對輸出進行排序比從頭開始生產要容易得多,這個過程可以更有效地擴大規模。
Proximal Policy Optimization (PPO) 步驟:它是獎勵模型用于進一步微調和改進 SFT 模型的步驟,這一步的結果就是所謂的政策模型,會根據代理正在采取的行動和收到的獎勵不斷調整當前策略,而且它將策略的變化限制在與先前策略的一定距離內。
所以在基于人工標注者輸入的基礎上進行不斷強化的訓練,本質上他們賦予了ChatGPT的回答。有了RLHF人類反饋中的強化學習,ChatGPT在訓練循環中使用人類反饋來最大限度地減少有害、不真實和/或有偏見的輸出。
當然有了算法,還需要儲存處理數據和運算處理的計算中心,ChatGPT背后的計算中心是微軟的Azure云計算中心。
三、ChatGPT的局限性
那么如此強大的ChatGPT的局限性在熟悉了它背后的核心技術之后可能就明白了,它是基于人類語言文字超大數據積累訓練而來,它無法具備思維和創新,主要是基于過去被訓練的數據組合而來。
另外對于準確性來講,當前使語言模型更準確的兩個核心相關的功能:
LLM 從外部來源檢索信息的能力。
LLM 為他們提供的信息提供參考和引用的能力。
所以ChatGPT的答案僅限于已經存儲在其訓練的信息中,例如我們現在用的ChatGPT就是基于2021年之前的網絡數據以及相關書本知識進行學習訓練的。在其靜態權重中捕獲。(這就是為什么它無法討論 2021 年之后發生的事件,當時模型已經過訓練。),如果能夠從外部來源獲取信息將使 LLM 能夠訪問最準確和最新的可用信息,即使當該信息經常變化時(例如,公司的股票價格),但顯然目前不行。

另外就是人工強化訓練的人工標注者賦予的微調,也是當前ChatGPT的局限所在,首先ChatGPT擺脫不了人工標注者的影子例如立場,偏好等。
四、ChatGPT國內外有哪些同類產品?
那么類似于ChatGPT是不是就一枝獨秀?其他人都沒有此類產品?其實如上文講到ChatGPT屬于LLM大型語言模型一種,大型語言模型其實在很多互聯網公司都有,至于為什么是新勢力Open AI先釋放引起轟動,其實對于傳統勢力來講最怕犯錯,所以給了新勢力勇敢試錯的機會。

其實國外著名的語言模型除了來自 OpenAI的GPT-3 、還有:
Google的PaLM或LaMDA;
Meta 的Galactica或OPT;
Nvidia/Microsoft 的Megatron-Turing;
AI21 Labs 的Jurassic-1;
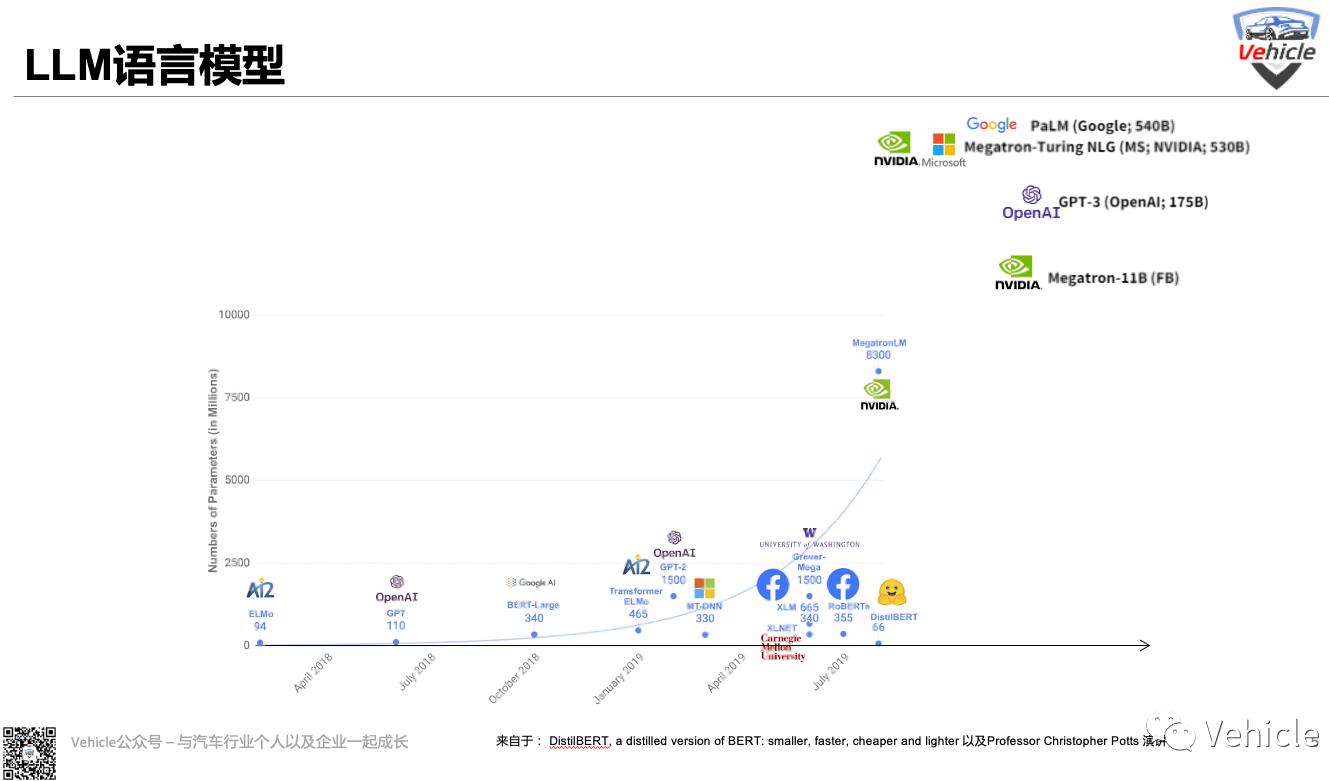
當然除了以上國外的Amazon、Microsoft、GitHub、Apple、IBM等也構建了提供不同特性和功能的自然語言處理框架。其中包括數字助理、預測編碼工具和聊天機器人,也包含大型語言模型。
國內的Baidu已投入開發類似ChatGPT的相關技術,該項目名字確定為文心一言,英文名ERNIE Bot,3月份完成內測后面向公眾開放。目前,文心一言在做上線前的沖刺。
阿里巴巴,根據其內部一名資深技術專家爆料,阿里達摩院正在研發類ChatGPT的對話機器人,目前已開放給公司內員工測試。
另外人工智能聊天軟件在國內各大應用平臺上并不陌生,如微信官方的小冰,字節跳動旗下的猜猜,騰訊的DOGE,訊飛語音小秘書,圖靈機器人等。但這些都不具備如ChatGPT的人工智能效應,大多數并未達到良好的用戶體驗。但現今有了ChatGPT的成功案例,估計會引發一波國內語言聊天軟件和硬件的升級。但算法的差距,有國內某技術大佬說,中國和國外相差兩年以上。
五、ChatGPT對于汽車技術有什么影響?
那么對于,我們熟悉的汽車行業呢?ChatGPT對于汽車產品和技術有什么影響?先問問萬能的ChatGPT。

首先從產品上來講,改變語音控制,改變汽車語音助手可能是最快和最直接的方式了,大模型下的語言訓練,可以通過微調進入汽車領域用于汽車語音識別系統,幫助駕駛員實現語音控制,如語音導航,電話,音樂等。
最典型的有通用的安吉星服務,未來恐怕只需要ChatGPT了。另外座艙語音助手可能兼容座艙控制和聊天服務,變得更加智能和人性化聊天,達到我之前座艙文章《智能座艙系列文一,他到底是什么?》中描述的更加懂人類。
之后從汽車客戶服務上來講,幫助提供快速,準確和個性化的客戶服務,從而提高客戶滿意度。以后的客服電話恐怕都會快速向ChatGPT類似方案靠攏。所以,從產品應用上來講,ChatGPT短期內催生汽車語言控制的升級,催生更加智能的語言助手。產品開發流程上來講可能催生車企內部的知識流程積累。從產品服務上來講,ChatGPT短期內會改變售前售后的客服方式,長期可能也改變售后維修診斷方式。
至于對于汽車技術的影響,以語言算法Transformer為基礎的ChatGPT獲得了極大的轟動,那么無疑給基于視覺算法為基礎的智能駕駛一劑強心劑,畢竟當前智能駕駛的圖像算法很多是借鑒自更前一步的語言算法。例如Transformer最早被特斯拉應用在其智能駕駛上,目前基本上國內所有智能駕駛的算法都在朝這個方向跑。
六、總結
最后Meta AI 負責人楊立昆Yann LeCun近日表示:“就底層技術而言,ChatGPT 并沒有特別的創新。這不是革命性的,盡管這是公眾對它的看法。只是,你知道,它組合得很好,做得很好。”

AI人工智能的底層三大件,數據,算力,算法的發展給ChatGPT的出現提供了爆發的基礎,Open AI 將它組合的很好,不但是算法而且還包括了算力,數據。
數據方面,互聯網的幾十年高速發展,積累了海量人類的文本。
算力方面,計算機技術的發展,從芯片的制程到類似Chiplet,等助力AI芯片蓬勃發展。
算法,從神經元算法起步,到Transformer 等各類算法的爐火純青的應用。
所以AI底層三大件的發展,一定會催生出更多類似于ChatGPT的通用人工智能應用,但我們更應該關注底層三大件的發展,未來數據類似于寶藏和礦產,例如Jack的文章就是私人數據和寶藏,一定可以微調一個數據模型用來套任何課題;芯片算力,成了決勝AI的大器,沒有芯片那么數據礦產無法挖掘;算法,猶如礦藏提純配方。
未來做好AI三大件的工作,才能在AI時代贏得紅利。
參考文章以及圖片
Training language models to follow instructions with human feedback - Long Ouyang等;
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter - Victor SANH等;
來源:Vehicle Pirate Jack






